


Model Problems
No, we are not talking about anorexia, cocaine, or Tom Brady. We are talking about the problems inherent with atmospheric dispersion models and their application to hazardous materials releases and CBRN incidents. These really come down to two basic issues: the problems inherent to the different models and the misuse of these models.
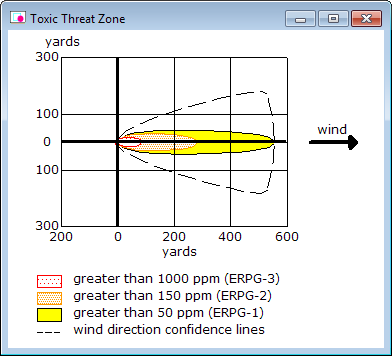
Talking about this. (An ALOHA model, Courtesy: Environmental Protection Agency).

Definitely NOT this. (Courtesy: Wikipedia Commons)
The inherent problems are a technical issue, but one that is easily explained without getting too technical (according to MS Word this post is at a 11.8 grade level!). There are tons of different dispersion models. See a good list here. As you can see, most use something called “Gaussian dispersion,” which if you are so interested, you can learn all about here. The biggest problem with such models is that they assume that in any release, the chemical of concern mixes immediately with the atmosphere so that the concentration is like a bell curve, i.e. the highest concentration is down the center of the cloud. This problem is inherent to basic dispersion modelling software like the EPA’s CAMEO/ALOHA suite.
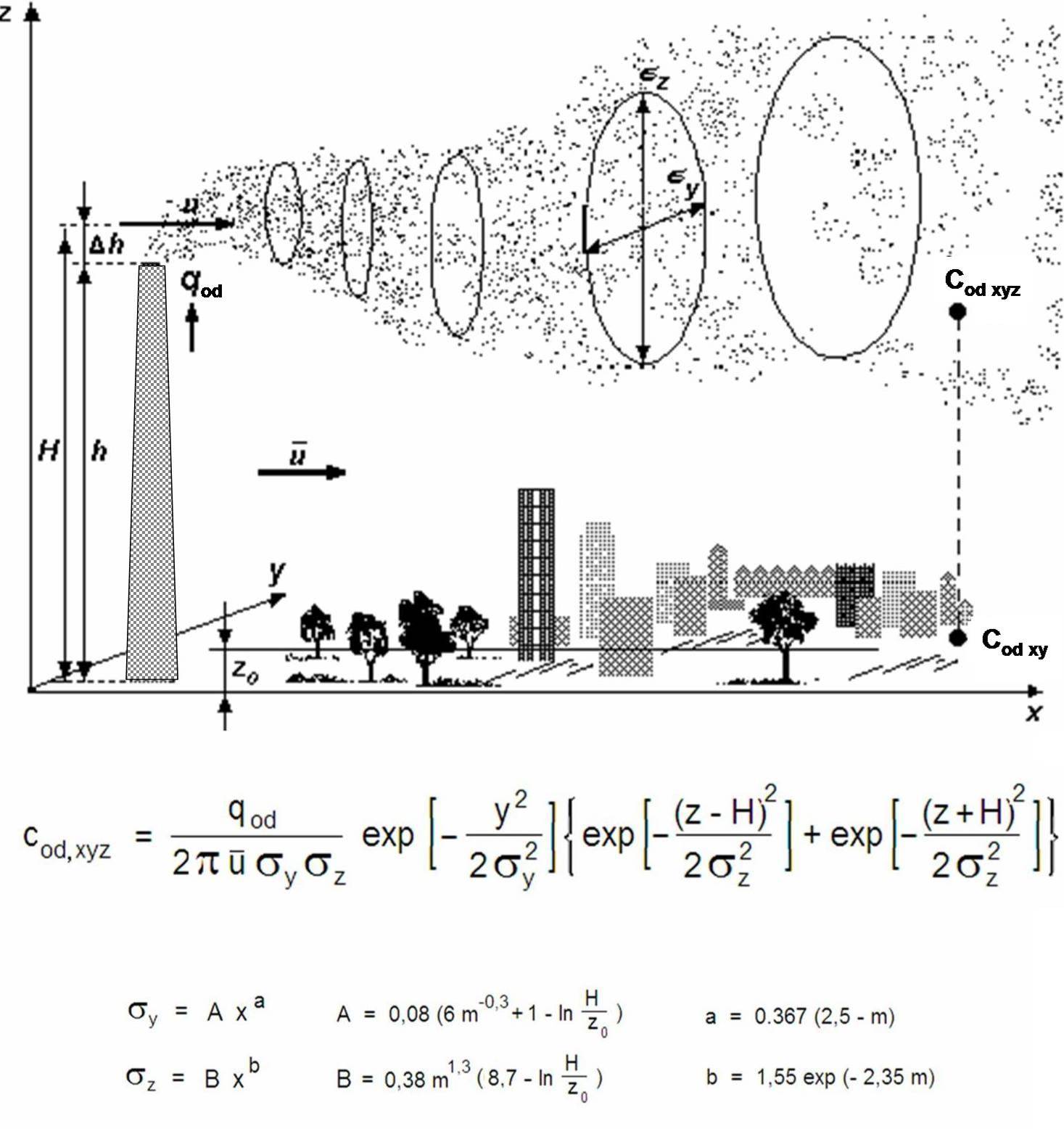
Agraphic representation of a Gaussian Dispersion Plume Model with equations (Courtesy: Wikipedia Commons)
While such models provide “close enough” concentration estimates for many conditions, those models become problematic when conditions reduce mixing in the atmosphere, specifically at low wind speeds (less than 3 miles per hour) where concentrations in reality tend to remain higher especially at the source. In such conditions, modelling software like ALOHA will offer incorrect models. Likewise, very stable atmospheric conditions like those associated with low-lying fog, produce concentrations that tend to remain high far from the source, contrary to what the model will predict.
What does that mean? That means that if you are modelling a chemical attack or a release in the early morning or night and using a Gaussian based model like ALOHA to do it, your model will be inaccurate. If you know from reading your chemical warfare history or remember your old FM 3-3, early morning and atmospherically stable periods are prime times for battlefield chemical attacks.
Basic models like ALOHA have other issues. Specifically they fail to account for:
- Byproducts from fires, explosions (combustion) or chemical reactions – specifically they assume that the release does not react with air or water vapor, even though many chemicals do. That means that a chemical released may not be the chemical that is actually in the plume!
- Particulates – ALOHA and most basic Gaussian dispersion models cannot do particles, dust, or other solid material, which rules out radioactive material among other things.
- Chemical mixtures – Basic modeling only does pure chemicals and a small number of solutions.
- Wind shifts and terrain steering – Basic models assume wind speed and direction are constant throughout the downwind area. In reality, this is usually not the case. This is especially true in in built up or urban areas, or where there are significant transitions in terrain. For example, an open area that transitions to a heavily forested one or the bottom of a valley versus the hilltop overlooking it. This effect is “terrain steering” and is the result of wind shifting speed and direction as it crosses varied terrain. In urban areas, large buildings create all sorts of eddies and currents impossible to model. This is particularly problematic in areas like stadiums or certain facilities where wind can “swirl” and create a cyclonic effect or in major metropolitan areas like Manhattan or Downtown Chicago where the skyscrapers create a wind tunnel effect.
- Terrain – This relates to the item above. Basic models assume flat terrain, though adjustments are possible for “roughness.” Such models do not predict pooling or sloping ground effects, so liquids and gases that might settle in a depression will not show up. Think of it this way – an ALOHA model of a chlorine release in World War I would fail to predict the way the gas settled into trenches and shell holes, which was also true of liquid mustard contamination which tended to flow into and collect in such depressions (along with rain water).
- Fragments – an explosive event scatters both debris and material. Basic dispersion models do not predict fragment trajectories. Therefore, if the release involves the scattering of say a liquid or solid that subsequently vaporizes, reacts, or disperses due to fire; those new release points are not in the model, which only has the single release point of the explosions origin. So basic dispersion models have trouble with liquid agents delivered by artillery and/or dispersed by explosive charges, especially if that release involves multiple rounds or bomblets.
(Note: The above list is adapted from the one here.)
That does not mean that the big brains have not tried to alleviate some of these problems. There are many variations of dispersion models. The Defense Threat Reduction Agency (DTRA) Hazard Prediction and Assessment Capability (HPAC) and its associated Consequence Assessment Tool Set/Joint Assessment of Catastrophic Events (CATS-JACE), are CBRN equivalent of ALOHA/CAMEO and use a variety of underlying models like SCIPUFF or PUFF-PLUME (for radioactive material) to try to offset some of the problems inherent in basic Gaussian models like those used by ALOHA. However, these complex models have their own issues. The reason there are so many different models is that no one model fits every circumstance. More importantly, there are hosts of things no model can address. You wouldn't ask Kate Moss to model plus size bathing suits, and you'd never ask a supermodel which set of snow tires is best for your old Bronco.
There is one other big problem with all dispersion models. For large areas (say a county in Oklahoma) and big dispersals (like an industrial facility), assuming you are using the right model and give it accurate inputs the results will be, while not perfect, close enough to be useful for decision making. They are “good-enough” models but should not be confused with reality, which is always inherently more complicated. This all falls apart however when you attempt to do “indoor” modelling or highly localized models. The smaller the model the more inaccurate it is, likewise if you try to model really big things (like the atmospheric dispersion of radioactive material from Chernobyl or Fukushima) your model will similarly fall apart after a certain point. Trying to get an accurate model of something so vast is like asking Zoolander to turn left.
Both of these circumstances (modelling too small or too big an event) suffer inordinately from the “butterfly effect.” That effect, which comes from the problems inherent with weather forecasting models, is based on a discovery where a meteorologist using what was then thought to be the most accurate model for predicting weather increased the accuracy of his input by one decimal place (let’s say from 1.355 to 1.3545), and got a complete different forecast.[i] The example from which the effect gets its name is that if a butterfly flaps its wings in Japan you might end up with a thunderstorm over Oklahoma.
That very example, which comes from atmospheric models (after all, weather forecast models are at their core, atmospheric models), demonstrates the problems of modeling in a nutshell. A dispersion model is no more accurate than your local weather forecast. In fact, models are heavily dependent on weather, which programs like HPAC can account for, but only to a point. Further, the more inputs you have for the model, the more likely a change in one can have an outside effect on all the others, and our atmosphere has an awful lot of variables.
This problem of “micro-climates” makes urban dispersion models, small facility models, and indoor modeling impossible. Despite many attempts to come up with a good enough version, none works. As one DARPA scientist who attempted it a number of years ago explained to me, “You open a door a ¼ of an inch one time, or a ½ inch another and you get a completely different model. It can’t be done,” he explained. A similar attempt to produce models at a chemical production facility produced the same problem. Too many atmospheric variables – valves switching on and off, steam and heat producing eddies in the air, people walking about, vehicles coming and going; all produced atmospheric disturbances that changed the outcome. There were too many variables, many of them random.
For very large dispersion models encompassing the worldwide effects of say, radiation released by Chernobyl, the number of variables is even greater. Such models are good enough only in that weather forecasts are good enough. Based on atmospheric data a weather forecaster might predict lower or higher temperatures across a wide area (Western Europe or California) but his accuracy in predicting the actual high and low temperature in your neighborhood will have a greater degree of error associated with it – they might get within a few degrees or so. So is it with any dispersion model, you can make some broad generalizations, but specificity in your prediction is subject to wider error.
Here are two good rules of thumb about all dispersion models: One, know your models and their limitations. Two, don’t try to get too granular or detailed – the closer and smaller in size you get, the less accurate it is.
While there are hosts of other inherent issues with atmospheric dispersion models, the real problem isn’t often the models themselves but the way people misuse them. From bad data (the GIGO problem) to failing to understand the limitations of the model in use, there are hosts of bad modeling decisions made across the CBRN community every day. The most fundamental error is failing to understand that the models are not exactly predictive, even the highly complicated ones. The real world will be different from the model.
By this point, you are probably thinking, “Why model at all then?” Well, there are many good reasons, but any modeler or CBRN professional needs to understand how to use them and present them. The following are CBRNPro.net’s suggestions, helpfully organized into a top ten list.
10. Never ever hand a plume model to a first responder or anyone that is not a CBRN professional without extensive explanation – or better yet, don’t do it – even to so-called “professionals” use the model to create another, more broadly outlined product (see #9).
9. Give them a plume model overlaid with an old-fashioned circle and cone of uncertainty overlay instead. Better yet, only give them circle/cone models.
8. If you are a decision maker, incident commander, or ground maneuver unit, and someone approaches you with a plume model, ask him or her if they know what Gaussian diffusion is. They don’t need to explain or understand differential equations, but if they have no idea what it is, or its limitations, ignore any model they give you.
7. Use models to focus your air monitoring and contamination surveys. Do not assume the model is remotely accurate until you confirm some part of it on the ground, in the real world.
6. Remember a model is only approximate (within known limitations). It is also a snapshot in time. Weather and other variables change. Know how and when to account for those changes.
5. Sometimes, it is better to use the “old fashioned way,” like a simple nomogram for a nuclear weapon, rather than a fancy model. The error probability is higher, but the errors are more likely to fall to the safe side.
4. Models are only as good as the data that feed them. The more complex the modelling software suite (HPAC) the more variables there are. If a modeler cannot explain more than half of the variables, or provide solid data for them, the model is less than worthless.
3. If you are modelling many unknowns, it is better to be safe than sorry. Assume the worst, but be ready to explain it as a worst-case scenario and discount your results. Better yet, don’t run a model until you have more data. Use a big circle cone model and only make assumptions you can confidently make and even then, worst case those.
2. Never, ever, ever, attempt to present a plume model as accurate inside a major urban area, in highly varied terrain, or in unique release points with significant microclimates or terrain steering problems (like open air stadiums). Better yet, don’t model them at all. Use a circle/cone overlay instead, or just explain what is more likely (from urban canyons or stadiums, or in areas with significant depressions, etc.).
1. If you have something fancy, like HPAC/CATS-JACE, know when to use it and for what: Nuclear weapons models outputs are good (they are the original basis of the program), but only if you know or can accurately estimate the yield and have access to good weather data. Radiation Dispersal Devices suffer a major GIGO problem, by the time you know the explosive charge and size of the original radioactive source in the RDD you won’t need a model anymore. Chemical models are not bad, though not necessarily better than ALOHA if you lack accurate input data. Biological agents are always problematic. Lastly, in nearly every case it is better to leave natural disasters (i.e. Hurricane) to the National Weather Service or NOAA.
Finally, and this is true in all cases, if you cannot explain more than half the variable inputs for any model, don’t use the model, even a slight change to one can produce dramatically different results and you need to know what each does. Instead remember that for most Hazmat/simple incidents, ALOHA or a circle/cone based on the North American Emergency Response Guide (ERG) is probably better for decision-making, as long as you re-evaluate regularly for weather shifts or changes in variables.
There you have it: Model problems that don’t involve Jay Cutler, Tyra Banks, or eating disorders. Of course, there is one other rule of CBRN that is always worth repeating: Know which way is upwind and uphill and when in doubt, keep calm and decon.
[i] Incidentally, this problem is a major point of contention when discussing “climate models” used in the debate over greenhouse gas emissions and “global warming/cooling” or climate change. It is a common complaint of scientists that policy makers who use their climate models do not understand their inherent complexities or problems.




